

High-Level Architecture Overview of my CSL Datahub implementation
Understanding the structure, roles, and data flow of my implemented CSL Datahub
Series: Designing a Microservice-Friendly Datahub
PART III — CASE STUDY: MY CSL DATAHUB IMPLEMENTATION
Previous: Introducing my CSL Datahub implementation: Context and Constraints
Next: The Web App of my CSL Datahub implementation
This is the point in the series where abstraction gives way to structure.
Up to now, we’ve talked about why Datahub architectures exist and what patterns they rely on. This article answers a different question: what does the whole system actually look like when assembled? Not in fragments, not in isolated diagrams—but as a living pipeline where data originates, moves, transforms, and settles.
The goal here is simple: by the end of this article, you should be able to mentally simulate the CSL Datahub.
Disclaimer (Context & NDA)
The CSL Datahub implementation described here was designed and built in 2021. While the architectural principles remain valid, some tooling choices could be updated today. To comply with NDA requirements, business-specific logic, schemas, and sensitive details are intentionally generalized.
The Big Picture: A System of Roles, Not Services
At a high level, the CSL Datahub consists of five major roles:
CSL Web App – the source of truth
Redis Streams – the event buffer
Processor Service – the translator and orchestrator
RabbitMQ – the inter-module communication backbone
External Modules – independent consumers and producers

Each role has a narrow responsibility. None of them are interchangeable. Together, they form a pipeline where state changes become events, and events become reactions.
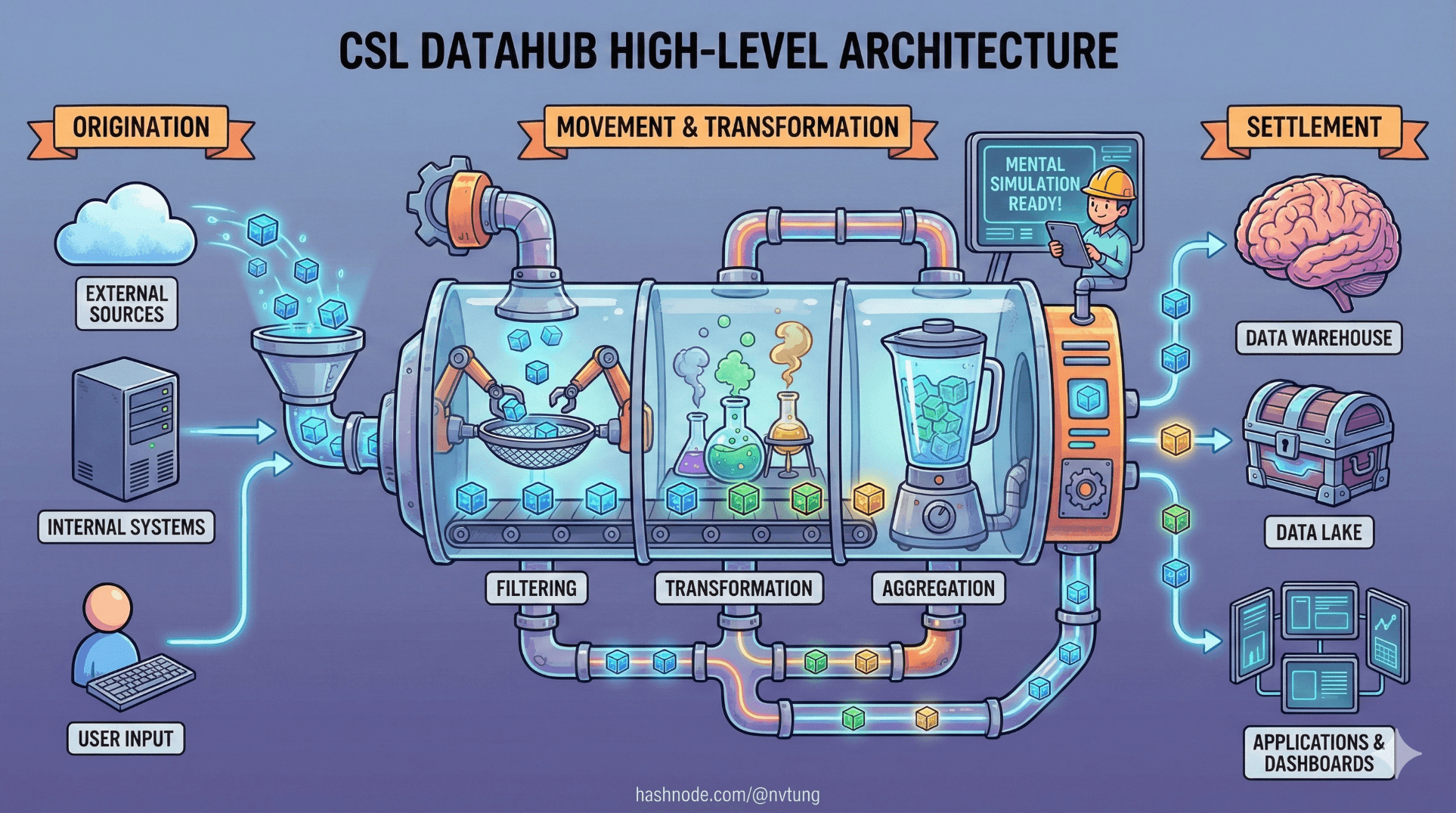
Full Architecture Overview (Narrative Diagram)
Instead of jumping straight into a static diagram, let’s describe the system in motion.
[ CSL Web App ]
|
| (state change)
v
[ MySQL Database ]
|
| (emit event)
v
[ Redis Streams ]
|
| (consume & translate)
v
[ Processor Service ]
|
| (publish events)
v
[ RabbitMQ Exchange ]
|
| (fan out)
v
[ Other Modules ]
This is not a call chain. It’s a propagation chain.
For the full and detailed architecture overview of my implemented CSL Datahub, below is the diagram (which has been made into a more fun version instead of the original boring one):

Component by Component
1. CSL Web App — The Source of Truth
The CSL Web App is where authoritative data lives.
Responsibilities:
Handle user interactions
Execute business rules
Persist state to MySQL
Emit events after state changes
Non-responsibilities:
No direct RabbitMQ access
No orchestration of downstream services
No knowledge of consumers
A typical flow inside the app looks like this:
// Update domain state
$user->updateProfile($data);
$user->save();
// Emit an event
$redis->xAdd(
'csl:events',
'*',
[
'event' => 'user.updated',
'user_id' => $user->id,
'occurred_at' => time()
]
);
Notice the order:
State is written
An event announces that it happened
The event does not cause the change. It describes it.
2. Redis Streams — The Event Buffer
Redis Streams act as the shock absorber between the web app and the rest of the system.
Responsibilities:
Buffer events durably enough
Absorb bursts
Allow consumers to lag safely
Provide replay via consumer groups
Redis Streams do not:
Route messages
Enforce business meaning
Replace message brokers
They exist to protect the core system from downstream variability.
3. Processor Service — Translation, Not Authority
The Processor is the most misunderstood component, so its boundaries matter.
Responsibilities:
Consume Redis Stream events
Call CSL APIs when needed
Publish normalized events to RabbitMQ
Handle retries and failures
Non-responsibilities:
No authoritative state
No business ownership
No cross-domain decisions
Example Redis → RabbitMQ flow:
var entries = redis.StreamReadGroup(
"csl-consumers",
"processor-1",
"csl:events",
">");
foreach (var entry in entries)
{
var message = MapToMessage(entry);
PublishToRabbitMQ(message);
redis.StreamAcknowledge(
"csl:events",
"csl-consumers",
entry.Id
);
}
The Processor is a bridge, not a brain.
4. RabbitMQ — The Communication Backbone
RabbitMQ is where inter-module communication happens.
Responsibilities:
Route events to interested consumers
Decouple producers from consumers
Provide delivery guarantees
Enable fan-out
Publishing is intentionally simple:
channel.BasicPublish(
exchange: "csl.events",
routingKey: "user.updated",
body: payload
);
Consumers bind to what they care about. The producer never knows who they are.
5. External Modules — Autonomous Reactors
External modules are independent systems that:
Consume CSL events
Maintain their own derived state
React according to their own rules
Optionally publish events of their own
They:
Do not query CSL databases
Do not depend on CSL deployment cycles
Do not require CSL availability to function long-term
This is where scalability—in both traffic and teams—actually happens.
Responsibility Boundaries (The Most Important Part)
Let’s make the boundaries explicit.
| Component | Owns State | Emits Events | Routes Events | Applies Business Logic |
| CSL Web App | ✅ | ✅ | ❌ | ✅ |
| Redis Streams | ❌ | ❌ | ❌ | ❌ |
| Processor | ❌ | ✅ | ❌ | ⚠️ (translation only) |
| RabbitMQ | ❌ | ❌ | ✅ | ❌ |
| External Modules | ✅ (local) | ✅ | ❌ | ✅ |
When these boundaries blur, architectures degrade.
Where Data Originates
All authoritative data originates in one place:
- The CSL Web App’s database
Everything else is:
A reaction
A projection
A derivative view
This prevents:
Split-brain state
Conflicting writes
Ownership ambiguity

How Changes Propagate
A single change flows like this:
User action updates CSL state
CSL emits an event
Redis buffers it
Processor translates it
RabbitMQ distributes it
Modules react independently

No step requires synchronous coupling.
No step requires global knowledge.
Why This Structure Holds Under Pressure
This architecture survives because:
Failures are isolated
Time is allowed to exist
Components scale independently
Ownership is explicit

It’s not the simplest possible design—but it’s simple enough to reason about when things go wrong.
And they will.
Mental Simulation: A Quick Test
If you can answer these questions, you understand the system:
Where does truth live?
What happens if the Processor stops?
What happens if RabbitMQ is slow?
Who can safely retry?
Who can evolve independently?

The answers are visible in the structure itself.
Where We Go Next
Now that the big picture is clear, it’s time to zoom in.
In the next article, The CSL Web App: State, APIs, and Event Emission, we’ll focus on the heart of the system—how the legacy PHP application safely emits events without becoming tightly coupled to the rest of the Datahub.
Architecture makes sense when you can see it move.




