

Core Building Blocks of a Microservice-Friendly Datahub
Understanding the essential components behind scalable Datahub architectures
Series: Designing a Microservice-Friendly Datahub
PART I — FOUNDATIONS: THE “WHY” AND “WHAT”
Previous: Event-Driven Architecture Fundamentals
Next: Datahub Technology Choices: Tools That Fit the Pattern
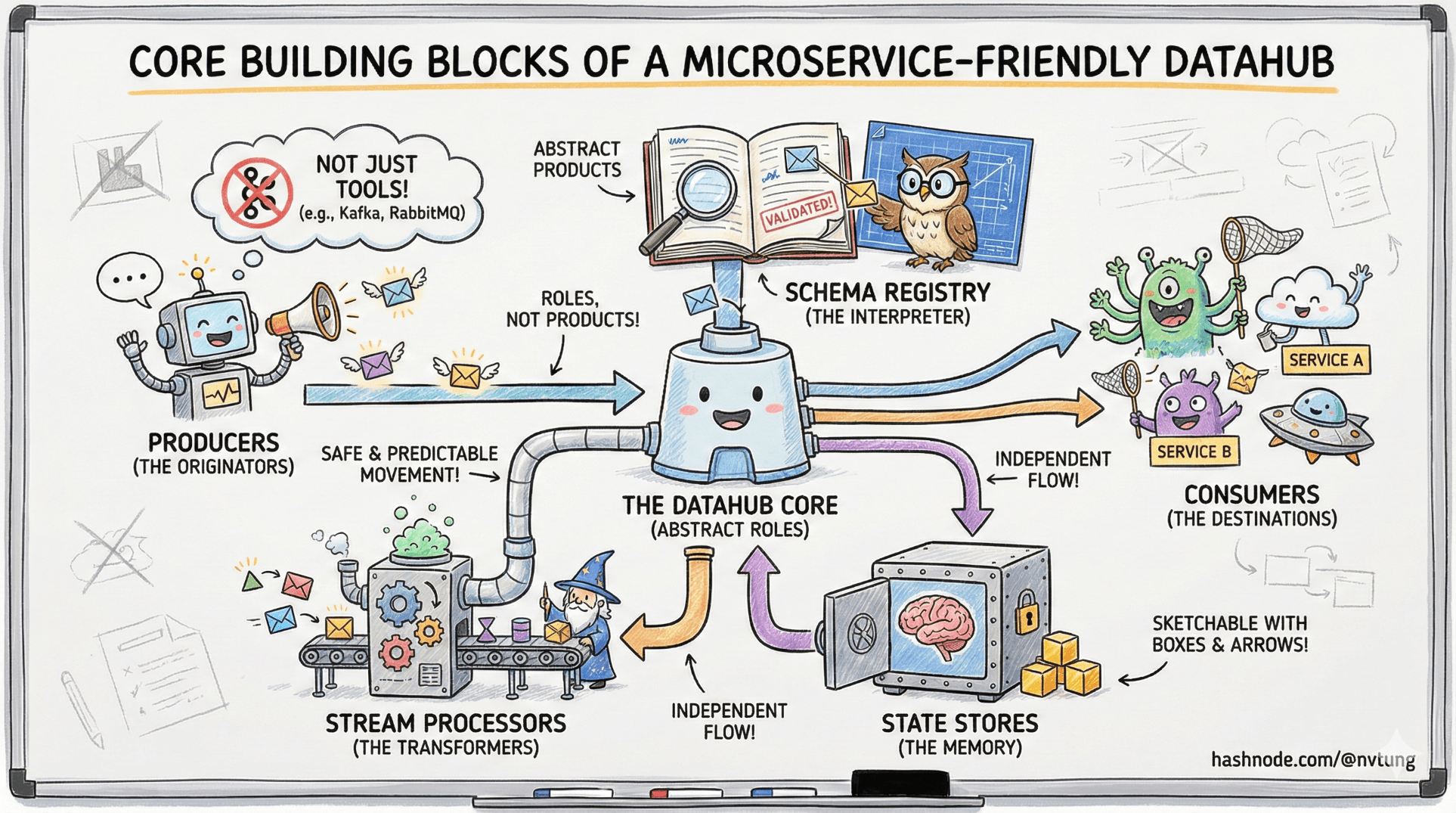
One of the fastest ways to misunderstand a Datahub architecture is to ask, “Which tools should I use?” too early.
A Datahub is not defined by RabbitMQ, Kafka, Redis, or any other recognizable logo. It’s defined by roles—distinct responsibilities that, when combined, allow data to move safely, predictably, and independently across a distributed system.
This article strips away product names and focuses on the abstract building blocks that appear in every well-designed, microservice-friendly Datahub. Once you understand these blocks, you should be able to sketch the architecture on a whiteboard using only boxes and arrows—and have it still make sense.
Start With the Principle: Separation of Concerns
Every scalable architecture obeys the same quiet rule:
each component should do one thing, and do it well.
Datahub architectures work because they refuse to blur responsibilities. They separate:
Communication from computation
State from events
Coordination from execution

When these concerns mix, systems become rigid. When they’re cleanly separated, systems evolve.
Everything that follows flows from this idea.
Message Brokers: The Communication Backbone
At the center of a Datahub sits a message broker.
Abstractly, a message broker is responsible for:
Receiving messages (events)
Routing them to interested parties
Buffering when consumers are slow
Decoupling producers from consumers
What it doesn’t do is interpret business meaning.

Message brokers operate in the data plane: they move information, but they don’t decide what that information means. This distinction is critical. The moment business logic leaks into the broker layer, you’re building centralized control instead of distributed communication.
A Datahub without a broker is just a set of services hoping for the best.
Event Buffers: Absorbing Time and Pressure
Closely related—but conceptually distinct—are event buffers.
An event buffer exists to absorb:
Bursts of activity
Temporary consumer outages
Differences in processing speed
Buffers turn time into a first-class concept. They allow producers to move forward even when consumers can’t keep up.

In some architectures, the broker itself provides buffering. In others, buffering is handled by a separate component. The key idea is not where buffering happens, but that it happens deliberately.
Without buffers:
Spikes cause failures
Backpressure propagates upstream
Systems synchronize unintentionally
Buffers protect independence.
API Gateways: Controlled Entry Points
Even in event-driven systems, APIs don’t disappear. They change role.
An API gateway (or controlled API layer) exists to:
Expose stable, intentional interfaces
Protect internal systems from direct access
Enforce validation, auth, and throttling
In a Datahub architecture, APIs are often used for:
Queries (read models)
Administrative commands
External integrations
Controlled state changes

APIs belong to the control plane. They define who is allowed to ask for what, not how data flows internally. Mixing API concerns with event propagation creates systems that are difficult to reason about and harder to secure.
Processors and Workers: Where Logic Lives
If the broker moves messages, processors and workers are where meaning is applied.
A processor:
Consumes events
Applies business rules
Produces new events or side effects
Interacts with APIs or databases
This is where transformation happens. Crucially, processors are replaceable and scalable. You can run many of them. You can version them. You can pause or replay them.

This keeps logic at the edges, not the center.
In a healthy Datahub:
The hub moves data
The edges interpret it
That inversion is what keeps systems flexible.
Databases as Sources of Truth (Not Integration Tools)
Every domain has data that must be authoritative somewhere.
In a Datahub architecture:
Databases are sources of truth
They are not shared integration points
They are not queried across service boundaries
A database answers one question only:
“What is the current state for this domain?”

Changes to that state are announced as events. Other services react to those events, not by reaching into the database, but by maintaining their own derived views.
This separation prevents:
Schema coupling
Accidental dependency chains
Cross-team data entanglement
State is owned. Data is shared through facts, not tables.
Control Planes vs Data Planes
A useful lens for understanding Datahub architecture is separating control planes from data planes.
Control Plane
APIs
Configuration
Auth and policy
Administrative actions
Control planes define intent.
Data Plane
Events
Message routing
Streams and buffers
Data planes define movement.

Mixing the two creates systems that are hard to secure and impossible to evolve safely. Datahub architectures work because they keep intent and movement distinct.
Why “One Tool Per Responsibility” Matters
Tool sprawl is not the real danger. Responsibility sprawl is.
Problems arise when:
Brokers execute logic
Databases trigger workflows
APIs orchestrate async pipelines
Processors store authoritative state
Each shortcut feels efficient in isolation. Together, they form a knot.

A microservice-friendly Datahub resists this by enforcing:
Clear boundaries
Explicit contracts
Single-purpose components
This makes systems slightly more verbose—and vastly more understandable.
The Whiteboard Test
Here’s a simple test for architectural clarity:
If you remove all product names and replace them with roles, does the system still make sense?
You should be able to draw:
A source of truth
An event publisher
A buffer
A router
A processor
A consumer
And explain how data flows between them without saying how it’s implemented.

If you can do that, the architecture is sound. Tool choice becomes an optimization problem, not a design crisis.
Why These Blocks Matter Together
Individually, none of these components are revolutionary. Together, they form a system that:
Tolerates failure
Encourages autonomy
Scales with teams
Evolves without rewrites

That’s the real promise of a Datahub—not complexity reduction, but complexity organization.
Where We Go Next
Now that we understand the building blocks, the next step is choosing how to assemble them responsibly.
In the next article, we’ll move from patterns and pitfalls to practice, exploring how these architectural ideas map to real tools—and why choosing the right tool matters more than choosing the popular one.




