

Event-Driven Architecture Fundamentals
Understanding events, retries, and consistency in async systems
Series: Designing a Microservice-Friendly Datahub
PART I — FOUNDATIONS: THE “WHY” AND “WHAT”
Previous: What Is a Datahub in Microservice Architecture?
Next: Core Building Blocks of a Microservice-Friendly Datahub
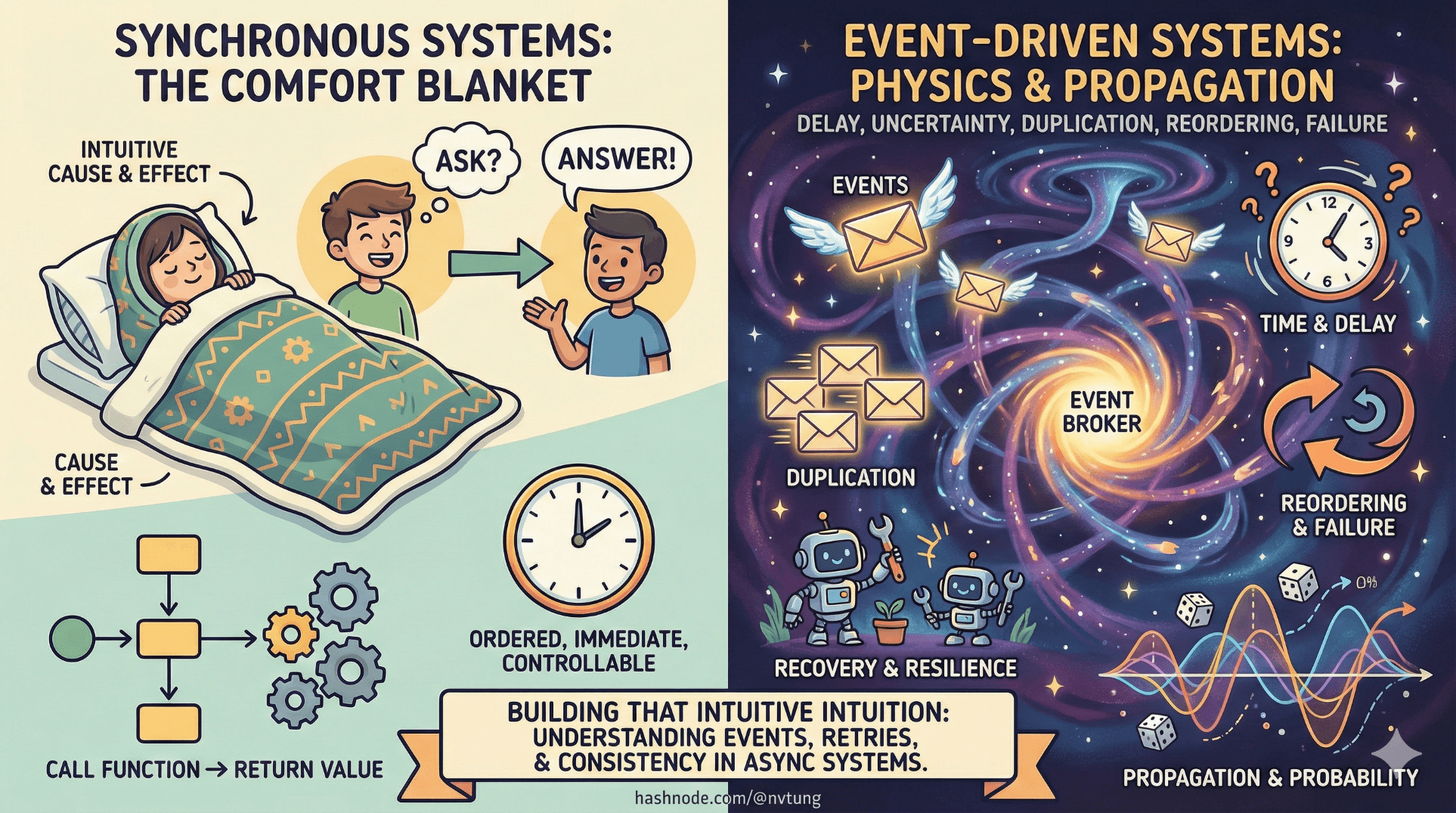
If synchronous systems feel intuitive, it’s because they flatter our human sense of cause and effect. You ask a question, you get an answer. You call a function, it returns a value. Everything feels ordered, immediate, and controllable.
Event-driven systems remove that comfort blanket.
They introduce delay. Uncertainty. Duplication. Reordering. Failure. And yet—at scale—they are often more reliable than the neat, synchronous systems they replace. The trick is understanding that event-driven architecture doesn’t operate on “software intuition,” but on something closer to physics: time, propagation, probability, and recovery.
This article is about building that intuition.
Events, Commands, and Queries: Stop Mixing Them
One of the fastest ways to get confused in asynchronous systems is to treat all messages the same. They are not.

Commands
A command is a request for action.
“Create order.”
“Send email.”
“Recalculate balance.”
Commands imply:
Intent
A specific target
An expectation that something should happen
They are directional and responsibility-heavy.
Queries
A query asks for information.
“What is the order status?”
“How many users exist?”
Queries imply:
A synchronous response
No side effects
A need for freshness
Queries and async systems rarely mix well.
Events
An event states a fact.
“Order created.”
“Payment failed.”
“User profile updated.”
Events imply:
Something already happened
No expectation of response
No control over who listens
This distinction is critical.
Event-driven architecture works because it shifts systems from telling others what to do to announcing what has happened. That single change removes an enormous amount of coupling.
Producers and Consumers: Who Knows Whom?
In synchronous systems, callers know callees. In event-driven systems, producers don’t know consumers exist.
A producer:
Emits events
Owns the meaning of the event
Does not care who consumes it
A consumer:
Subscribes to events
Interprets them for its own needs
Can appear or disappear without affecting producers

This asymmetry is deliberate. It allows systems to grow sideways—new consumers can be added without touching existing code. That’s not a convenience feature. It’s a scalability requirement.
Delivery Semantics: Why “Exactly Once” Is a Trap
People often ask:
“Can we guarantee exactly-once delivery?”
In practice, no. And trying to approximate it usually causes more harm than good.
Instead, distributed systems choose between two imperfect—but manageable—options.

At-Most-Once Delivery
Messages may be lost, but never duplicated.
This is fast and simple—but dangerous. Silent loss is catastrophic in data-driven systems. If an event disappears, downstream state may never recover.
At-Least-Once Delivery
Messages may be duplicated, but not lost.
This is slower and messier—but safer.
Event-driven systems overwhelmingly choose at-least-once delivery, because duplication is survivable, loss is not.
This is a foundational principle. Everything else—idempotency, retries, deduplication—exists to support it.
Why Duplication Is Safer Than Loss
Loss creates unknowns.
If an event disappears:
You don’t know which consumer missed it
You don’t know which state is now incorrect
You can’t reliably reconstruct history
Duplication creates annoyances, not mysteries.
If an event appears twice:
You can detect it
You can ignore it
You can design for it

Reliable systems are not those that prevent bad things from happening—they are those that recover predictably when bad things happen.
Eventual Consistency: Consistency Over Time, Not Instantly
Event-driven systems rarely offer immediate global consistency. Instead, they offer eventual consistency.
This means:
Different services may see different states temporarily
Data converges over time
The system tolerates delay
This is not a flaw. It’s a trade-off.

Trying to enforce immediate consistency across distributed services requires:
Locks
Coordination
Tight coupling
Fragile dependencies
Eventual consistency accepts that time is part of correctness.
Why Time Matters More Than Order
A common mistake is obsessing over perfect ordering.
In distributed systems:
Networks delay messages
Retries reintroduce old events
Parallelism breaks sequence assumptions
What matters is not strict order, but causal meaning.

Questions to ask instead:
Can this event be applied more than once?
Does processing this late cause harm?
Can state converge even if events arrive out of order?
Designing with time in mind produces systems that heal themselves. Designing with order obsession produces systems that deadlock.
Idempotency: The Superpower of Async Systems
Idempotency means doing the same thing twice has the same effect as doing it once.
In event-driven systems, idempotency is not an optimization. It’s survival gear.
Common strategies:
Deduplication keys
Versioned updates
Upserts instead of inserts
Natural idempotency through state checks

When consumers are idempotent:
Retries are safe
Duplication is harmless
Recovery is possible
Without idempotency, retries become threats instead of tools.
Why Retries Are Inevitable
Retries aren’t a sign of failure. They are a sign of realism.
In distributed systems:
Networks fail
Services restart
Timeouts happen
Messages get delayed
Retries turn temporary failure into eventual success.
The goal is not to eliminate retries—it’s to design so retries don’t break correctness.

This is why:
Side effects must be controlled
State transitions must be defensive
Consumers must tolerate repetition
Retries are the system breathing. Don’t suffocate them.
The Mental Shift: From Control to Resilience
Synchronous systems optimize for control.
Event-driven systems optimize for resilience.
That shift can feel uncomfortable at first. You no longer know exactly when something happens. You stop assuming linear cause-and-effect. You start thinking in flows, not calls.

But once that shift happens, something powerful emerges: systems that bend instead of break.
Why This Matters for a Datahub
A Datahub architecture amplifies everything discussed here.
It assumes:
Events are primary
Asynchrony is normal
Duplication is acceptable
Recovery is expected

Without understanding these fundamentals, a Datahub becomes a source of confusion instead of clarity. With them, it becomes a force multiplier.
Where We Go Next
Now that we understand the physics of asynchronous systems, the next step is practical.
What components do you actually need to build this?
How do message brokers, streams, processors, and APIs fit together?
In the next article, we’ll break down the core building blocks of a microservice-friendly Datahub, moving from theory into concrete architectural structure.
Async systems aren’t chaotic.
They’re just honest about how the world works.




