

Introduction to Designing a Microservice-Friendly Datahub
Designing event-driven systems that scale without coupling
Series: Designing a Microservice-Friendly Datahub
Next: The Problem Space before Datahub
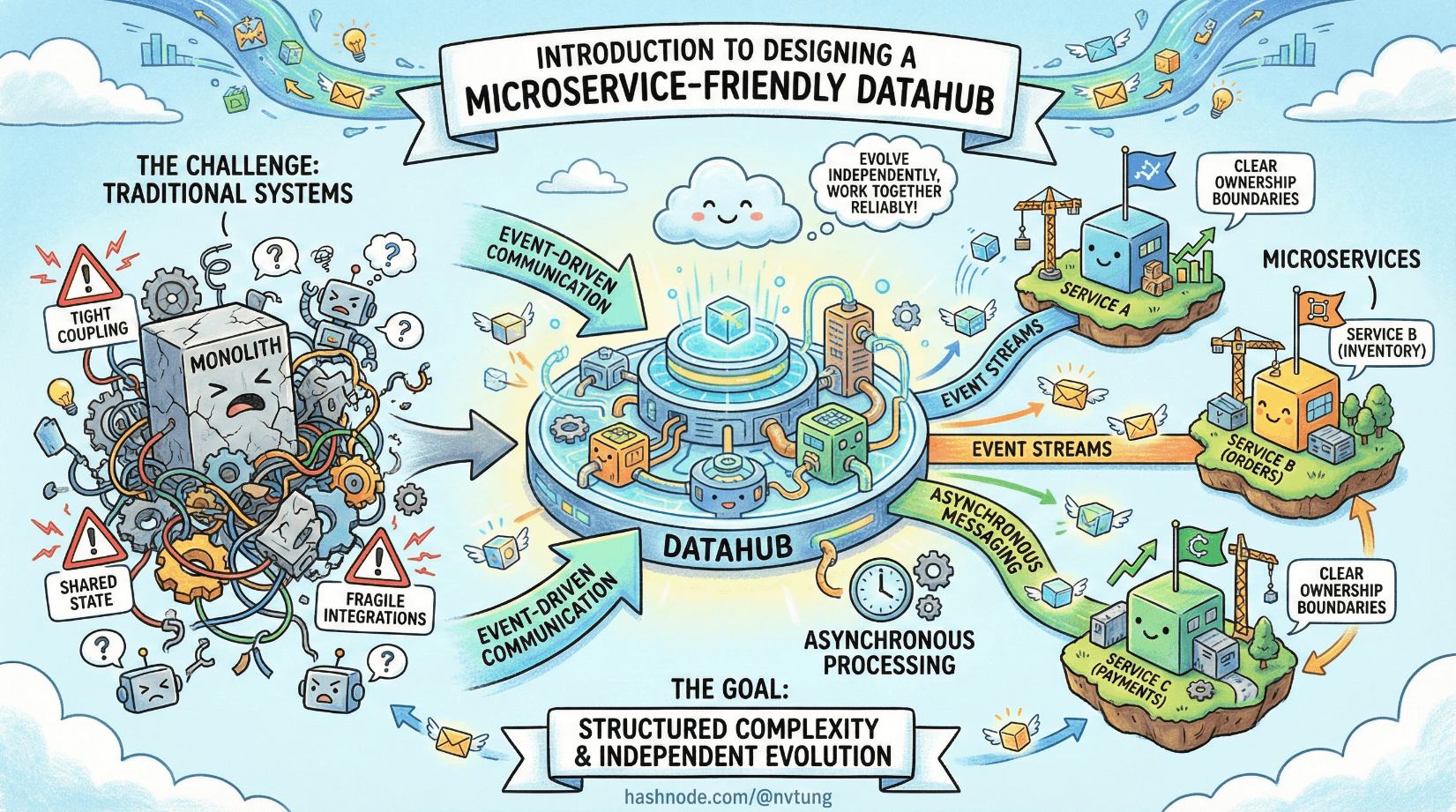
Modern enterprise systems don’t usually fail because of bad code. They fail because their components become too tightly coupled, too dependent on shared state, or too fragile to change without breaking something else. As systems grow beyond a single team or a single codebase, communication patterns—not frameworks—become the real architectural challenge.
This series explores microservice-friendly Datahub architecture as a practical response to that challenge. Rather than relying on point-to-point integrations or tightly synchronized APIs, a Datahub-centered approach embraces event-driven communication, asynchronous processing, and clear ownership boundaries. The goal is not to eliminate complexity, but to structure it in a way that allows systems to evolve independently while still working together reliably.
We’ll begin by grounding the discussion in fundamentals: why traditional architectures struggle at scale, what event-driven systems actually mean in practice, and which design principles matter most when multiple services need to exchange data without stepping on each other. From there, we’ll look at common architectural patterns, best practices, and the real trade-offs involved in choosing tools like message brokers, streams, and background processors.
The second half of the series moves from theory into reality. It breaks down a production Datahub implementation built to integrate a legacy web application with a growing ecosystem of independent modules. Using Redis Streams, RabbitMQ, REST APIs, and a dedicated processor service, we’ll walk through how data is produced, buffered, routed, consumed, and observed—along with the lessons learned along the way.
This is not a framework tutorial or a vendor comparison. It’s a guided exploration of how distributed systems actually communicate, how architectural decisions hold up under real constraints, and how to design a data exchange layer that can survive growth, change, and imperfect conditions.
Disclaimer:
- The real-world implementation discussed in this series was designed and built in 2021. While the core architectural principles remain valid, some technology choices or patterns may have evolved since then.
- Specific business logic, data models, and sensitive details have been generalized or omitted to comply with NDA requirements.
SERIES GOAL
Audience
Mid–senior engineers
Architects-in-the-making
Engineers working in monoliths who feel the pain
Teams transitioning toward microservices or modular systems
Promise
By the end of the series, readers should:
Understand why Datahub-style architectures exist
Know how event-driven microservices communicate safely
Recognize common architectural pitfalls
See a complete, working enterprise-grade implementation
Be able to adapt the ideas to their own stack
HIGH-LEVEL SERIES STRUCTURE
The series should be split into two major arcs:
Foundations & Principles (conceptual, tool-agnostic)
Real-World Implementation Case Study (my CSL system)
This keeps it clean, pedagogical, and credible.
PART I — FOUNDATIONS: THE “WHY” AND “WHAT”
These articles establish shared vocabulary and mental models.
Article 1 — The Problem Space
Theme: Why traditional architectures break at scale
Core focus
Monolith pain points
Tight coupling
Database-sharing anti-pattern
Chatty synchronous APIs
Scaling teams vs scaling systems
Key ideas
Software architecture evolves with organization size
Data ownership becomes the real bottleneck
Communication patterns matter more than code quality
Outcome
Readers should feel the need for a different approach.
Article 2 — What Is a Datahub in Microservice Architecture?
Theme: Defining the concept clearly
Core focus
What “Datahub” means (not a product, but a pattern)
Difference between:
Point-to-point integration
Service mesh
Event bus
Datahub-style architecture
Why “hub” doesn’t mean “centralized logic”
Key ideas
Event propagation vs direct dependency
Loose coupling with strong contracts
Hub-and-spoke communication, not control
Outcome
Readers understand the architectural role of a Datahub.
Article 3 — Event-Driven Architecture Fundamentals
Theme: The physics of asynchronous systems
Core focus
Events vs commands vs queries
Producers and consumers
At-least-once vs at-most-once delivery
Eventual consistency
Idempotency
Key ideas
Why duplication is safer than loss
Why time matters more than order
Why retries are inevitable
Outcome
Readers stop fearing async systems and start reasoning about them.
Article 4 — Core Building Blocks of a Microservice-Friendly Datahub
Theme: Abstract components, not products
Core focus
Message brokers
Event buffers
API gateways
Processors / workers
Databases as sources of truth
Key ideas
Separation of concerns
Control planes vs data planes
Why “one tool per responsibility” matters
Outcome
Readers can sketch a Datahub on a whiteboard without naming any technology.
Article 5 — Technology Choices: Tools That Fit the Pattern
Theme: Mapping concepts to real tools
Core focus
Message brokers (RabbitMQ, Kafka)
In-memory systems (Redis)
REST vs messaging
Background workers
Polyglot services
Key ideas
Tradeoffs, not “best tools”
When RabbitMQ beats Kafka
When Redis Streams is “good enough”
Outcome
Readers understand why tools are chosen, not just which.
PART II — DESIGN PRACTICES: THE “HOW”
This section bridges theory into applied architecture.
Article 6 — Designing for Decoupling and Evolution
Theme: Architecting for change
Core focus
Avoiding shared databases
Contract-based communication
Event versioning
Backward compatibility
Key ideas
Change is guaranteed; breakage is optional
Consumers move slower than producers
Schemas are APIs
Outcome
Readers internalize long-term system thinking.
Article 7 — Reliability, Failure, and Observability
Theme: What happens when things go wrong
Core focus
Retries
Dead-letter queues
Poison messages
Monitoring pipelines
Backpressure
Key ideas
Failure is normal
Visibility is a feature
Silent failures are the real enemy
Outcome
Readers think operationally, not just architecturally.
Article 8 — Scaling Patterns and Anti-Patterns
Theme: What breaks first as load increases
Core focus
Processor bottlenecks
Message storms
Over-synchronous APIs
Over-centralized logic
Key ideas
Horizontal scaling realities
Avoiding “God services”
Knowing when to split components
Outcome
Readers learn to recognize architectural smells early.
PART III — CASE STUDY: MY CSL DATAHUB IMPLEMENTATION
Now the reader is ready. This is where credibility spikes.
Article 9 — Introducing the CSL Datahub: Context and Constraints
Theme: Real-world requirements
Core focus
Business context
Why microservices were needed
Constraints (legacy PHP app, multiple modules, language mix)
Non-goals
Key ideas
Architecture is shaped by constraints
“Perfect” architectures don’t exist
Outcome
Readers understand why my design looks the way it does.
Article 10 — High-Level Architecture Overview
Theme: The big picture
Core focus
Full architecture diagram
Major components
Data flow overview
Responsibility boundaries
Key ideas
Who owns what
Where data originates
How changes propagate
Outcome
Readers can mentally simulate the system.
Article 11 — The CSL Web App: State, APIs, and Event Emission
Theme: The source of truth
Core focus
PHP/Yii/Humhub role
MySQL usage
Redis Stream production
REST API boundaries
Key ideas
Why the Web App does not speak RabbitMQ
Protecting the core system
Outcome
Readers see how legacy systems fit modern patterns.
Article 12 — Redis Streams as an Event Buffer
Theme: The quiet hero
Core focus
Why Redis Streams was chosen
Consumer groups
Ordering and durability
Backpressure handling
Key ideas
Fast doesn’t mean reckless
Streams vs queues
Outcome
Readers appreciate Redis beyond caching.
Article 13 — The .NET Processor: Orchestration and Translation
Theme: The bridge service
Core focus
Responsibilities
RabbitMQ consumption
API calls to Web App
Message production
Key ideas
Why this service exists
How it prevents coupling
Risks of overloading it
Outcome
Readers understand the heart of the system.
Article 14 — RabbitMQ as the Inter-Module Backbone
Theme: Communication at scale
Core focus
Exchanges
Routing strategies
Consumers in other modules
Message flow patterns
Key ideas
Publish/subscribe in practice
Decentralized consumption
Outcome
Readers grasp multi-module coordination.
Article 15 — End-to-End Data Flow Scenarios
Theme: Following real events
Core focus
User-triggered update
Cron-triggered update
External module-triggered update
Key ideas
Event lifecycles
Idempotency in practice
Outcome
Readers see the system in motion.
Article 16 — Lessons Learned and Future Improvements
Theme: Architectural maturity
Core focus
What worked well
What was harder than expected
Bottlenecks discovered
Future evolution (Kafka, splitting processors, etc.)
Key ideas
Architecture is a living system
Reflection is part of engineering
Outcome
Readers walk away with wisdom, not just diagrams.
Optional Extra Articles
🧾 Event Contracts as APIs
♻️ Dead Letter Queues and Retry Strategies
🔍 Observability for Event-Driven Systems
⚖️ Redis Streams vs Kafka: Choosing the Right Event Backbone
🚦 When the Processor Becomes a Bottleneck




