

The Problem Space before Datahub
Why monoliths, shared data, and synchronous systems collapse as organizations grow
Series: Designing a Microservice-Friendly Datahub
PART I — FOUNDATIONS: THE “WHY” AND “WHAT”
Previous: Introduction to Designing a Microservice-Friendly Datahub
Next: What Is a Datahub in Microservice Architecture?
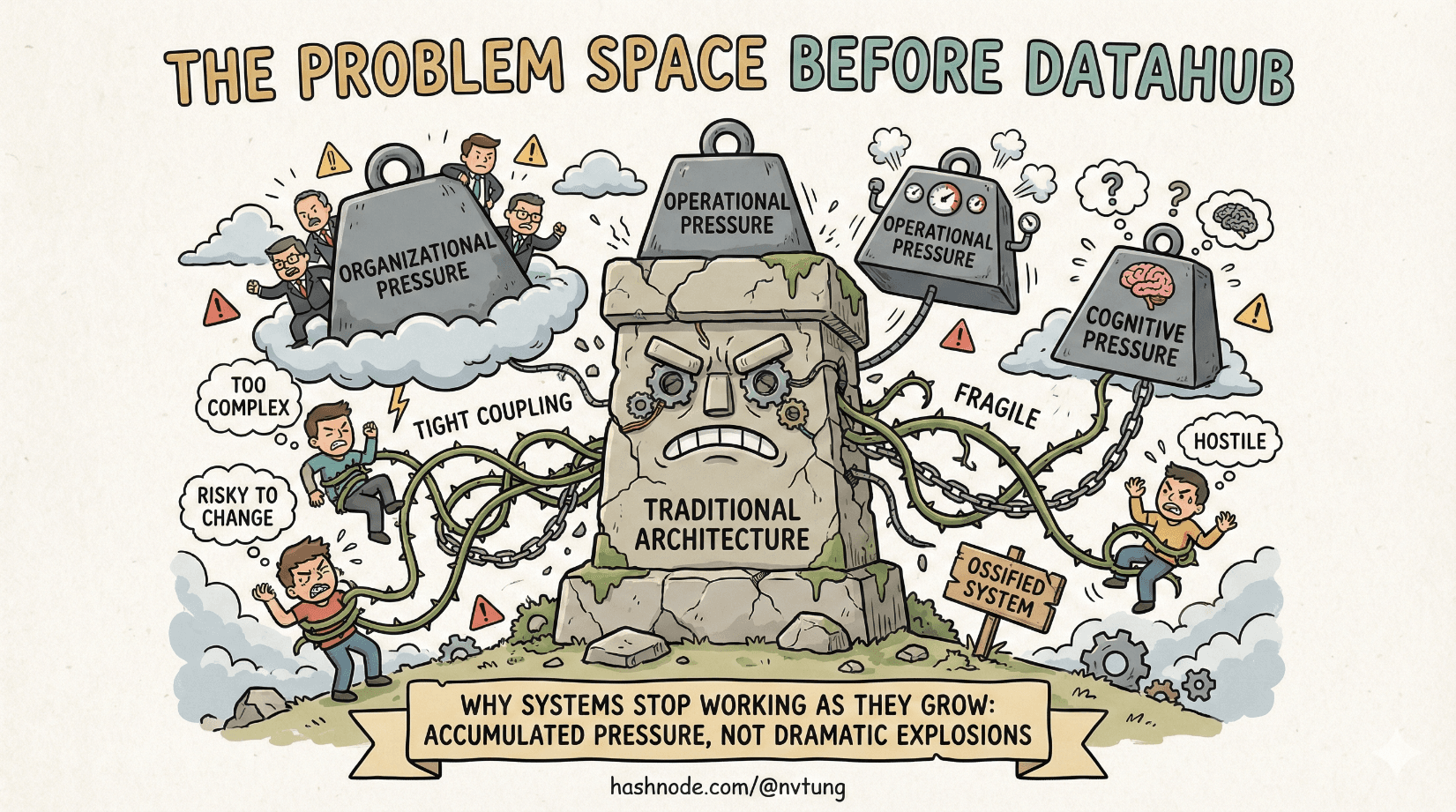
Software systems rarely collapse in dramatic fashion. They don’t explode; they ossify. What starts as a clean, understandable codebase slowly hardens into something brittle, risky to change, and increasingly hostile to the people maintaining it. By the time teams agree that “the architecture is the problem,” the system has usually been broken for years.
This article sets the stage for the rest of the series by answering a deceptively simple question: why do traditional architectures stop working as systems grow? The answer is not fashion, not hype, and not a sudden love for microservices. It’s pressure—organizational, operational, and cognitive pressure—that accumulates until old patterns fail.
The Monolith Isn’t the Villain—Until It Is
Monoliths are not inherently bad. In fact, they’re often the right choice early on.
A monolithic architecture gives you:
A single deployment unit
Shared in-process calls
Simple debugging
Straightforward data access
For a small team and a clear product direction, this is a superpower. The problem is that monoliths scale linearly in code, but exponentially in coordination cost.

As features accumulate, the monolith becomes:
Harder to understand holistically
Riskier to modify
Slower to deploy
Increasingly resistant to refactoring
At a certain point, the monolith stops being “one thing” and becomes many implicit systems forced to live in the same body. The architecture hasn’t changed, but the organization has—and that mismatch is where trouble begins.
Tight Coupling: The Silent Growth Killer
Tight coupling is rarely intentional. It emerges naturally when:
Modules share internal logic
Changes in one area require changes in many others
Assumptions leak across boundaries
In tightly coupled systems, everything knows too much. A small change—adding a field, renaming a column, adjusting a workflow—ripples outward in unpredictable ways. Engineers stop asking “what’s the best design?” and start asking “what’s the safest change I can make without breaking production?”

This leads to:
Fear-driven development
Over-testing trivial changes
Long release cycles
Accidental system-wide outages
The system becomes correct but fragile. Stable but immobile.
The Database-Sharing Anti-Pattern
If tight coupling has a physical form, it’s the shared database.
Multiple services—or modules pretending to be services—reading and writing the same tables creates an illusion of simplicity. There’s “one source of truth,” so everything must be fine. In reality, this is data coupling at its most dangerous.
Shared databases cause:
Implicit contracts that are never documented
Changes that break consumers silently
Inability to evolve schemas independently
Competing assumptions about data meaning

When every part of the system can reach into the same data store, ownership disappears. No one truly controls the data, but everyone depends on it. At scale, this becomes the single biggest bottleneck—not performance-wise, but organizationally.
Chatty Synchronous APIs: When Latency Becomes a Tax
As systems grow, teams often replace shared code with synchronous APIs. On paper, this looks like progress: services are “separate,” communication is “explicit,” and responsibilities are “clear.”
Until they aren’t.
Chatty synchronous APIs introduce:
Tight runtime coupling
Cascading failures
Latency amplification
Fragile dependency graphs

A request that once took milliseconds now hops across services, each with its own failure modes. When one service slows down, everything upstream slows down with it. Availability becomes the product of all dependencies instead of the responsibility of one system.
This is how distributed systems quietly reintroduce monolith-like fragility—just over the network.
Scaling Teams Is Not the Same as Scaling Systems
Here’s the uncomfortable truth: most architectural failures are organizational failures wearing technical masks.
As teams grow:
Code ownership fragments
Release schedules diverge
Risk tolerance varies
Local optimizations conflict with global stability

Architectures that worked for five engineers collapse under fifty—not because the code got worse, but because communication paths multiplied faster than structure.
If every team must coordinate with every other team to make progress, velocity approaches zero. Conway’s Law isn’t a theory here; it’s a warning label.
Data Ownership Becomes the Real Bottleneck
At scale, data is no longer just stored—it is interpreted.
Different teams want the same data for different reasons, at different times, under different assumptions. Without clear ownership:
No one knows who can change what
Schema evolution becomes political
Bugs turn into blame games
Innovation slows to a crawl

The question shifts from “how do we store data?” to “who owns the meaning of this data?” Traditional architectures don’t answer this well. They centralize storage but decentralize responsibility, which is the worst of both worlds.
Communication Patterns Matter More Than Code Quality
Well-written code can’t save a system with poor communication patterns.
At scale:
The cost of coordination dominates the cost of computation
Reliability is shaped by interaction, not implementation
Latency and failure are normal, not exceptional

Architectures optimized for in-process calls and shared state assume a world that no longer exists once systems become distributed. What matters then is not how elegant your classes are, but how change propagates through the system.
Why This Leads to a Different Approach
All of these pressures—tight coupling, shared databases, synchronous dependency chains, organizational growth—push systems toward a breaking point where incremental fixes stop working.
What’s needed isn’t just new tools, but a different way of thinking about communication, ownership, and change. One that accepts:
Asynchrony as normal
Failure as expected
Independence as a design goal
Data as a contract, not a shared resource
That shift is what the rest of this series explores.
In the next article, we’ll define what a Datahub architecture actually is, why it’s not just “another middleware layer,” and how it reframes system communication in a way that scales with both software and organizations.
The monolith didn’t fail because it was wrong.
It failed because the world around it changed.




