

What Is a Datahub in Microservice Architecture?
Understanding Datahub architecture as a pattern, not a product
Series: Designing a Microservice-Friendly Datahub
PART I — FOUNDATIONS: THE “WHY” AND “WHAT”
Previous: The Problem Space before Datahub
Next: Event-Driven Architecture Fundamentals
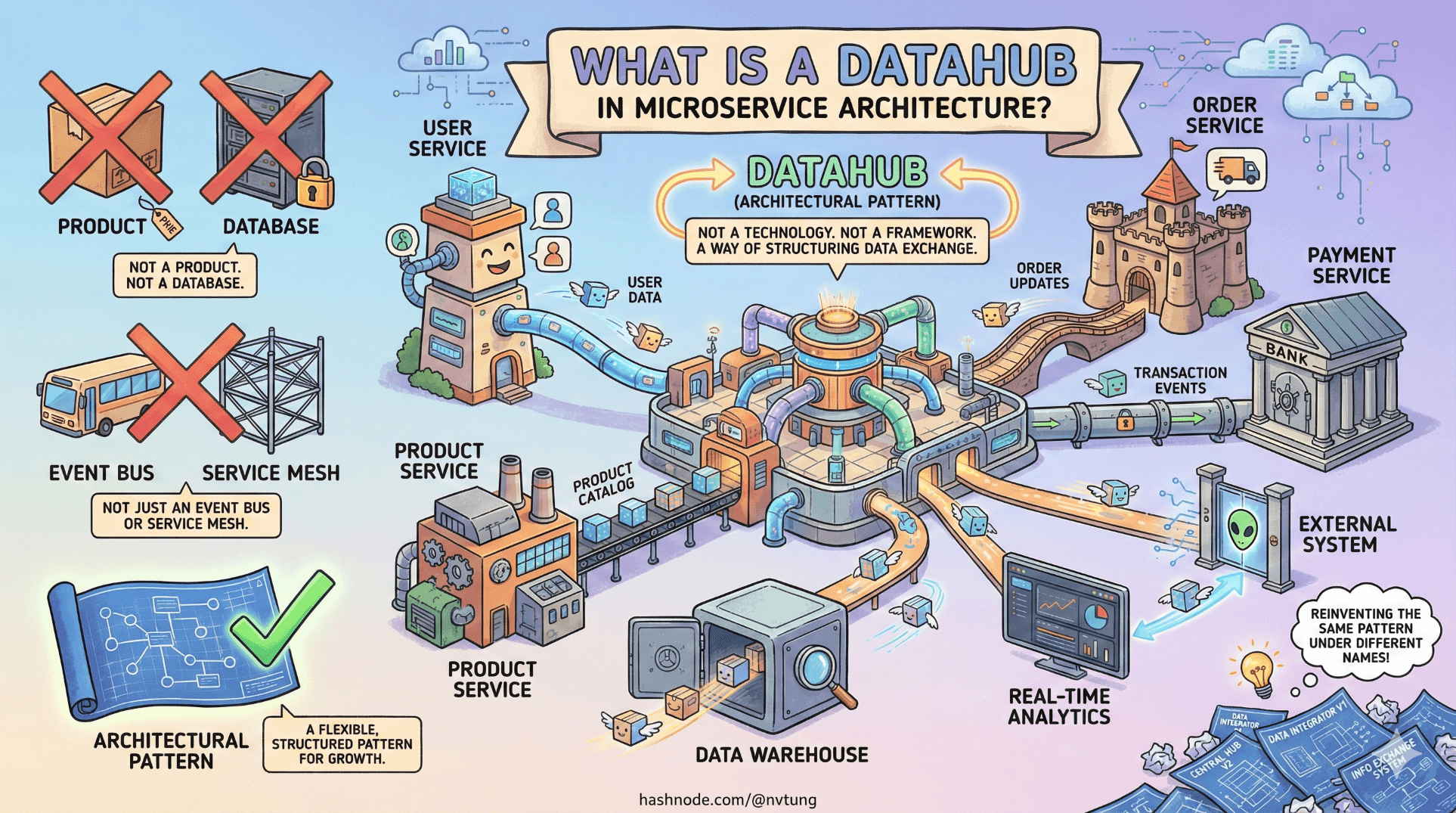
“Datahub” is one of those terms that gets used a lot and defined very little. Sometimes it sounds like a product. Sometimes it sounds like a database. Sometimes it’s confused with an event bus, a service mesh, or just “that thing in the middle.” None of those are quite right.
So let’s be precise.
A Datahub is not a technology.
A Datahub is not a framework.
A Datahub is an architectural pattern—a way of structuring how systems exchange data as they grow beyond simple, direct integrations.
Once you see it clearly, it becomes obvious why teams keep reinventing it under different names.
Start With the Real Problem: Communication, Not Services
Microservices are often described as “small, independent services.” That’s true, but misleading. The hard part is not splitting code into services—it’s deciding how those services communicate without becoming tightly bound to each other.
Every distributed system faces the same dilemma:
Services need data from other services
Services evolve at different speeds
Failures are inevitable
Teams need autonomy

A Datahub exists to solve communication at scale, not computation.
What “Datahub” Actually Means
At its core, a Datahub is a shared communication layer that allows systems to:
Publish changes as events
Consume data without knowing who produced it
Evolve independently without breaking others

The Datahub doesn’t own business logic. It owns data movement and propagation.
A useful mental model is this:
A Datahub is the place where facts about the system are announced, not where decisions are made.
That distinction matters.
Event Propagation vs Direct Dependency
Traditional systems rely on direct dependency:
Service A calls Service B
Service B must be available now
Service A must understand Service B’s API
Failures propagate immediately
A Datahub-based system relies on event propagation:
Service A publishes “something happened”
Service B consumes it when ready
No synchronous dependency
No assumption about who listens

This shift changes everything.
Direct dependencies scale poorly because they multiply. Event propagation scales because it decouples time, ownership, and responsibility.
How a Datahub Differs From Common Alternatives
To really understand the Datahub pattern, it helps to contrast it with other common integration approaches.

Point-to-Point Integration
This is the default starting point.
Service A talks directly to Service B, C, and D.
Each new requirement adds another connection.
Over time:
Dependencies form a web
Changes ripple unpredictably
Failure cascades are common
Ownership boundaries blur
Point-to-point integration optimizes for speed of initial development, not longevity.
A Datahub exists specifically to stop this pattern from spreading.
Service Mesh
A service mesh focuses on runtime communication concerns:
Traffic routing
Load balancing
Retries
Security (mTLS)
It operates at the infrastructure level.
A Datahub operates at the data and event level.
They solve different problems. A service mesh helps services talk safely. A Datahub helps services talk loosely. You can use both—but one does not replace the other.
Event Bus
An event bus is a technical component—a message broker or streaming platform that moves messages around.
A Datahub may use an event bus, but it adds structure and intent:
Defined event contracts
Ownership rules
Clear producer/consumer boundaries
Controlled entry points
An event bus without discipline becomes noise.
A Datahub is about curation, not just transport.
Datahub-Style Architecture
A Datahub-style architecture combines:
Event-based communication
Clear data ownership
Asynchronous propagation
Strong contracts
Instead of services calling each other directly, they:
Publish events into the hub
Subscribe to what they care about
Remain unaware of each other’s internal details
This is hub-and-spoke communication, not hub-and-spoke control.
Why “Hub” Does Not Mean Centralized Logic
The word “hub” makes people nervous—and rightly so. Centralized systems have a long history of becoming bottlenecks.
A Datahub avoids this by being logically central, not behaviorally central.
The hub:
Routes events
Buffers messages
Enforces contracts
The hub does not:
Decide business outcomes
Orchestrate workflows
Own domain rules
If business logic accumulates in the hub, you’ve built a monolith with better networking.

A healthy Datahub is boring.
Its job is to move information, not interpret it.
Loose Coupling With Strong Contracts
Datahub architectures are often described as “loosely coupled,” which is true—but incomplete.
They replace tight coupling with contractual coupling.
Instead of sharing:
Databases
Internal APIs
Implementation details
Services share:
Event schemas
Versioned contracts
Explicit data meaning
This is a trade-off, not a shortcut. Strong contracts require discipline, versioning, and coordination—but they scale far better than invisible dependencies.

Loose coupling without contracts is chaos.
Contracts without coupling is architecture.
Hub-and-Spoke Communication, Not Control
One of the most important mental shifts is understanding what the hub represents.
In a Datahub:
Spokes decide what to publish
Spokes decide what to consume
The hub doesn’t coordinate behavior
It only enables communication
No service asks the hub “what should I do?”
They announce facts and react to facts.

This keeps autonomy where it belongs: at the edges.
Why This Pattern Emerges Naturally
What’s interesting is that teams often arrive at a Datahub pattern accidentally.
They start with:
Shared databases → problems
Synchronous APIs → problems
Point-to-point integrations → problems
Eventually, someone says:
“Why don’t we just publish events and let others decide what to do?”
That sentence is the birth of a Datahub.

The pattern isn’t new. What’s new is recognizing it as a first-class architectural choice, not a workaround.
What This Enables
A well-designed Datahub enables:
Independent service evolution
Resilience to partial failure
Clear data ownership
Organizational scalability
Eventual consistency without chaos

Most importantly, it changes how teams think about systems—not as chains of calls, but as networks of facts.
Where We Go Next
Now that the concept is clear, the next question is unavoidable:
If systems communicate through events instead of calls, what does that actually look like in practice?
What patterns, guarantees, and trade-offs does event-driven architecture introduce?
That’s where we’re heading next.
In the next article, we’ll break down event-driven architecture fundamentals—and why embracing asynchrony is less scary, and far more powerful, than it first appears.




