

What Is BFF — and When Is It Actually Worth It?
The problem it solves, the cost it introduces, and the honest answer on when not to use it.
Your frontend has outgrown the API it was given.
At some point, most frontend teams hit the same wall. The backend exposes what it knows — resources, entities, service boundaries — and the frontend is left stitching four API calls into a single screen, massaging data shapes the UI never asked for, and writing adapter logic that has no good place to live. The Backend for Frontend pattern is the answer to that wall. But it comes with a cost: an additional service to build, deploy, and own. This series makes the case for that trade-off — and equally, for the cases where it is not worth making. The examples and architecture decisions throughout are drawn from a production implementation built for a Norwegian enterprise in the education sector. Where the original system cannot be described in full, concepts have been generalised to meet NDA obligations — but the engineering trade-offs, the failure modes, and the decisions that shaped the final design are real.
The problem, stated plainly
Before defining what a BFF is, it is worth being precise about what problem actually warrants one.
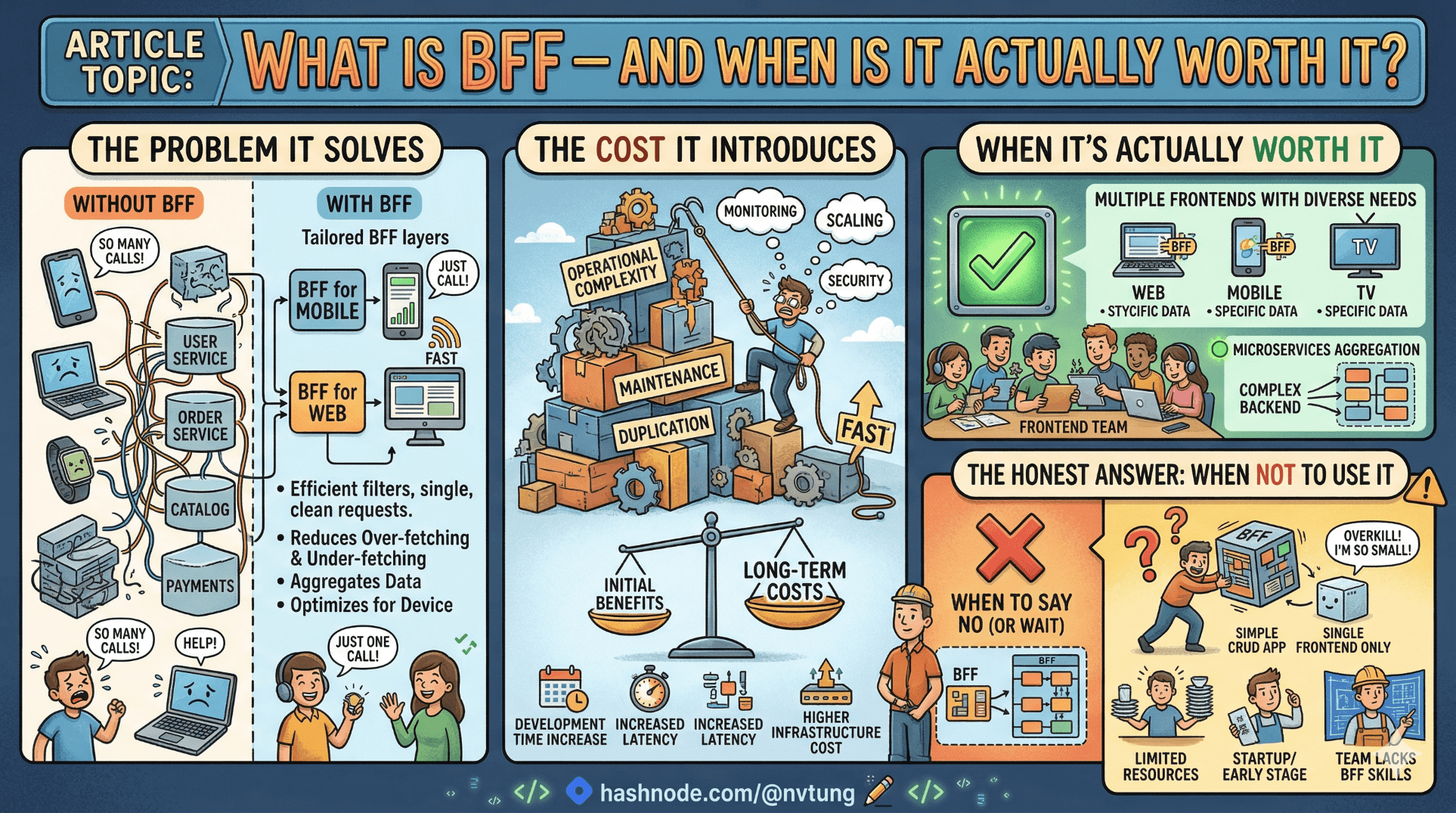
Imagine a dashboard screen in an education platform. It needs to render: the current user's profile and role, their organisation's enrolled courses, upcoming sessions for the current week, and unread notifications. In a system where services are organised around domain entities, that screen requires calls to at least four separate endpoints — likely across two or three different services. The responses come back in shapes optimised for storage and domain logic, not for what this particular screen needs.
The frontend handles it. It fires the requests, waits for them to resolve, merges the data, filters out the fields it does not need, transforms date formats, normalises inconsistent ID conventions between services, and then renders. This works. It is also a slow, fragile, and increasingly expensive pattern at scale.
Three specific failure modes appear consistently once systems grow:
Overfetching and underfetching. REST endpoints designed around domain entities return either too much or too little for any given screen. A GET /users/{id} response that includes billing history, audit logs, and security settings satisfies the account settings page — but it is wasteful when all the dashboard needs is a display name and an avatar URL. Conversely, a screen requiring data from three different resource types must make three round trips, each adding latency, each adding a potential failure point.
Adapter logic with no home. The gap between what upstream services return and what the frontend needs gets filled somewhere. In the absence of a dedicated layer, it lands in the frontend itself — in Vuex stores, in composables, in utility functions scattered across the codebase. This logic is hard to test in isolation, invisible to the backend teams who changed the API shape that broke it, and re-implemented separately for each client surface (web app, mobile app, third-party integration).
Security and session complexity pushed to the client. When the frontend talks directly to multiple APIs, it must manage tokens for each of them, handle token refresh across parallel requests, and decide what to expose in the browser. This is not where security boundaries should be drawn. The browser is not a trusted environment, and treating it as one creates problems that are difficult to retrofit away later.

None of these problems are fatal on their own, early in a product's life. The question is what you reach for when they compound — and BFF is one answer, not the only one.
What BFF actually is
The Backend for Frontend pattern, first articulated by Sam Newman in the context of microservices architecture, is straightforward in principle: create a dedicated backend service for each distinct frontend client, owned by the frontend team, whose sole responsibility is serving that client's specific needs.
The key words are dedicated and owned by the frontend team. A BFF is not a general-purpose API gateway. It is not a shared middleware layer. It is a service that knows exactly one consumer — your frontend — and is optimised entirely for that consumer's needs. It aggregates calls to upstream services, shapes responses into exactly what the UI requires, handles authentication at the boundary, and shields the frontend from the complexity and instability of the services behind it.

The Vue application has one API contract to reason about: the BFF. It does not know or care how many upstream services exist, how they are versioned, or what their response shapes look like. That complexity lives in the BFF, where it can be tested, versioned, and changed independently.
The BFF can do several things the frontend cannot do cleanly on its own: it can fire multiple upstream requests in parallel and merge the results before responding; it can cache aggressively for data that does not change per-request; it can enforce authentication and authorisation before a single upstream call is made; and it can translate between authentication contexts — for example, exchanging a session cookie for a service-to-service token without ever exposing a bearer token to the browser.
What BFF actually costs
This is where most introductory articles skip ahead too quickly. The BFF pattern is genuinely useful — but the version of it that works in production looks different from the version described in architecture blog posts, and the gap is filled with operational cost.
You are taking on a new service. This sounds obvious but its implications are underestimated. A new service means a new deployment pipeline, a new container to monitor, a new set of logs to aggregate, a new failure mode to handle, a new component in your runbook. If your team does not already own infrastructure or has not previously maintained a backend service, the operational learning curve is real. The BFF will go down. It will have bugs. It will need updating when upstream services change their contracts. These are not hypothetical costs — they are the routine maintenance costs of any production service, and they do not disappear because the service is thin.
The BFF becomes a coupling point. When your Vue application and your upstream services are decoupled by a BFF, the BFF is not free of coupling — it absorbs it. Every upstream API change that affects the frontend now requires a BFF change too. In a fast-moving system, this can mean the BFF becomes a bottleneck: a place where changes must land before they can reach the frontend. The team that owns the BFF becomes the team that must be unblocked first.
Latency is not free. A BFF adds one network hop between the browser and its data. For most production deployments — where the BFF and its upstream services are colocated in the same cloud region — this hop is in the single-digit milliseconds. But it exists, and for systems already operating close to latency budgets, it matters. The mitigation is co-deployment discipline and caching, both of which require deliberate effort.
The BFF can become a dumping ground. This is the failure mode no one talks about in architecture talks. A BFF that starts as a clean aggregation layer accumulates business logic over time. A validation rule here, a conditional transform there, a calculation that "just needs to live somewhere." Left unchecked, a BFF becomes a monolith with the word "frontend" in its name. The discipline to keep it thin — a translator and aggregator, not a domain engine — is cultural as much as technical, and it requires active enforcement.

When BFF is worth it
With that context established, the cases where BFF earns its overhead are clearer.
Multiple upstream services, single UI surface. If your frontend needs to aggregate data from three or more independent services for routine screens, the aggregation cost is already being paid somewhere. Paying it in the BFF — where it can be tested, cached, and monitored — is better than paying it in the client or across a distributed chain of sequential API calls.
Multiple client surfaces with diverging needs. A web application, a mobile app, and a third-party integration consume fundamentally different API shapes. A response payload appropriate for a desktop dashboard is wasteful over a mobile connection. A BFF per client surface means each client gets exactly what it needs, without the upstream services needing to know or care about client-specific requirements. This is the original use case Sam Newman described, and it remains the strongest one.
Security boundary clarity. If your system involves tokens that must never reach the browser, or authentication flows that require server-side session management — as is the case with Feide, the Norwegian government identity provider used in this series — a BFF gives you a clean place to draw the security perimeter. The BFF holds the session, manages token exchange, and the browser only ever receives a cookie. This is the Token Handler pattern, and it is substantially harder to implement correctly without a dedicated server-side layer.
Unstable upstream contracts. In a microservices environment where teams are moving fast and breaking things at the API layer, a BFF acts as a translation buffer. When an upstream service changes its response shape, you update the BFF. The Vue application is insulated. Without the BFF, that upstream change propagates directly into frontend code — often discovered at runtime rather than compile time.
Team ownership alignment. Perhaps the least technical but most practically important factor: if the frontend team has the capacity to own a backend service, a BFF gives them the autonomy to move at their own pace without being blocked on backend teams for API shape changes. This is an organisational argument as much as an architectural one, and it should be evaluated as such.

When BFF is not worth it
This section is the one most articles omit. The BFF pattern has a real overhead floor that you pay regardless of system complexity. Below a certain threshold, that floor is higher than the problems it solves.
Small teams moving fast on a single surface. If you have one frontend, one backend, and a team of three engineers, a BFF introduces a coordination overhead between your own people that does not exist if the frontend talks directly to the API. The aggregation and shaping problems are real, but they are solvable with thoughtful API design, GraphQL, or simply accepting a thin amount of adapter logic in the frontend until the system is large enough to justify more structure.
A well-designed monolithic API. If your backend already returns response shapes close to what the frontend needs — because the backend team works closely with the frontend team, or because the API was designed frontend-first — a BFF adds a layer without adding meaningful value. The problem a BFF solves is the impedance mismatch between backend domain models and frontend presentation needs. If that mismatch is small, the solution is disproportionate.
Early-stage products with unstable requirements. A BFF contract between the frontend and its upstream services is another API surface to maintain. In the early life of a product, when screen designs change weekly and domain models are still being discovered, the BFF becomes a change multiplier: every significant UI change requires a frontend change, a BFF change, and potentially an upstream change. The stability that makes a BFF valuable is the same stability that is absent in early-stage development.
Teams without infrastructure ownership. If your team has never maintained a deployed service — never dealt with container health checks, never written a deployment pipeline, never handled a 3am incident for something they own — adopting a BFF in production is learning two hard things simultaneously: the architecture and the operations. This is not a reason to avoid BFF permanently, but it is a reason to be honest about timing and capacity.

The decision framework
Rather than a checklist, use three questions. If the answer to fewer than two is "yes," the BFF overhead is likely not justified at this stage.
Does your frontend aggregate data from three or more independent services for routine operations? If most screens require only one or two API calls that already return the right shape, the aggregation value proposition is weak.
Do you have a meaningful security or session management requirement that cannot be cleanly handled in the client? If your authentication flow is stateless, token-based, and entirely client-managed, the security argument for BFF does not apply. If you are dealing with server-side sessions, token exchange, or an identity provider like Feide that requires server-side handling, it does.
Does your team have the capacity to own and operate a backend service independently? This means a deployment pipeline, monitoring, alerting, runbooks, and the willingness to be on-call for it. BFF without operational ownership is technical debt in a server rack.

What this series covers from here
The rest of this series assumes the answer is "yes, BFF is the right call." If it is not — if you read this article and concluded that your system is not there yet — the single most useful thing you can do is bookmark the decision framework above and revisit it in six months. Architecture decisions should trail system complexity, not lead it.
For those continuing: the next article addresses how to design the BFF contract itself — what belongs inside it, what must stay in upstream services, and how to version the API surface you are creating without recreating the problems you were trying to solve.
The implementation articles that follow use .NET Core Minimal APIs for the BFF service, Vue 3 composables for the client-side API layer, Feide for authentication, and Azure Container Instances for deployment. Each article is self-contained, but the architecture decisions made in the early articles carry forward — so reading in order is the path of least resistance.




