

Scaling Patterns and Anti-Patterns in Datahub
Recognizing bottlenecks and architectural smells as systems grow
Series: Designing a Microservice-Friendly Datahub
PART II — DESIGN PRACTICES: THE “HOW”
Previous: Datahub: Reliability, Failure, and Observability
Next: Introducing my CSL Datahub implementation: Context and Constraints
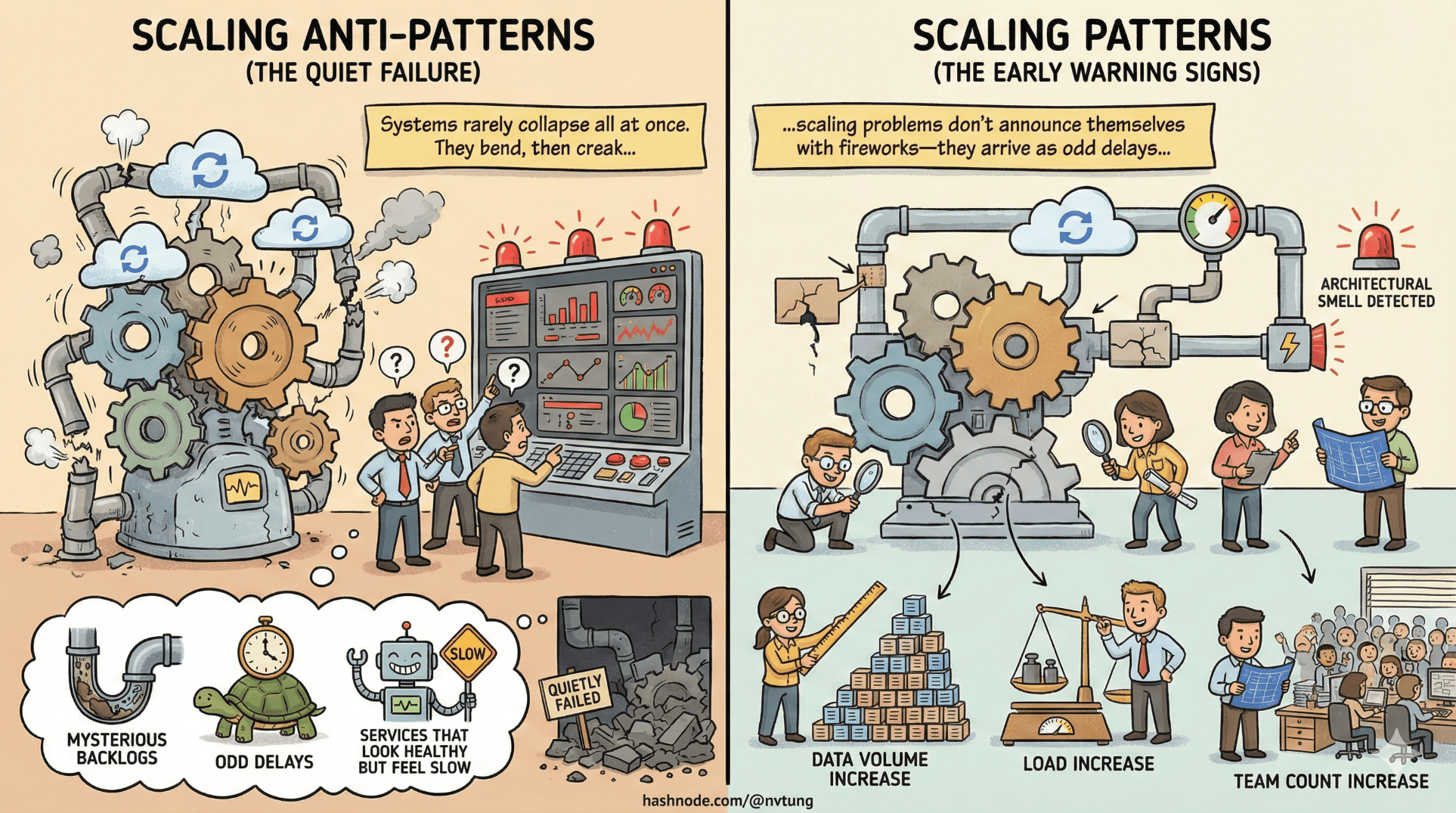
Systems rarely collapse all at once. They bend, then creak, then quietly fail in one corner while everyone argues about dashboards. Scaling problems don’t announce themselves with fireworks—they arrive as odd delays, mysterious backlogs, and services that look healthy but feel slow.
This article is about recognizing those early warning signs. Not performance tuning, not infrastructure tricks—but architectural smells that appear as load, data volume, and team count increase. Most of them are predictable. All of them are avoidable—if you notice them early.
Scaling Is Not About Speed—It’s About Pressure
When systems scale, three things increase faster than CPU usage:
Coordination
Coupling
Assumptions

You can add more instances to a service, but you can’t autoscale bad architecture. The first things that break are rarely databases or networks. They are decision points—places where too much responsibility has accumulated.
Processor Bottlenecks: When the Middle Becomes the Choke Point
In Datahub-style architectures, processors are powerful. They translate events, apply logic, and coordinate side effects. That power makes them dangerous.
A processor becomes a bottleneck when it:
Handles too many event types
Owns too much business logic
Performs synchronous calls inside async flows
Scales vertically instead of horizontally
Early symptoms include:
Growing queue lag
Uneven CPU usage
Increasing retry rates
“Just add more resources” becoming the default fix
The root problem isn’t load—it’s concentration of responsibility.

The Scaling Reality Check
Horizontal scaling only works when:
Work is stateless or partitionable
Responsibilities are narrow
Failures don’t cascade
If scaling a processor requires:
Shared in-memory state
Coordinated locks
Ordered execution across unrelated domains
…then the processor isn’t a worker anymore. It’s a coordinator pretending to be a worker.
Message Storms: When Events Amplify Instead of Inform
Event-driven systems can fail spectacularly—not by silence, but by noise.
A message storm happens when:
One event triggers many downstream events
Consumers emit new events for every reaction
Feedback loops emerge unintentionally
Common causes:
Events emitted on every state change
Lack of filtering or aggregation
Consumers reacting synchronously to async signals
No rate limiting at event boundaries
The system doesn’t slow down—it drowns itself.

Smell Test for Message Storms
If you ask:
“What happens when this event fires 10,000 times?”
…and the answer is:
“Everything wakes up.”
You have a storm brewing.
Healthy systems:
Emit fewer, more meaningful events
Aggregate changes where possible
Separate signal from noise
Events should inform, not panic the system.
Over-Synchronous APIs: The Return of the Distributed Monolith
One of the most common scaling regressions is accidental re-synchronization.
It usually starts innocently:
“We just need a quick API call here.”
“We need the result immediately.”
“It’s only one dependency.”
Then:
Latency chains form
Failure propagates upstream
Timeouts multiply
Availability becomes multiplicative
This is how distributed systems recreate monolith fragility—over the network.

The Telltale Signs
You’re drifting into over-synchronous territory if:
API calls appear inside event consumers
User requests depend on multiple services responding in real time
Timeouts are treated as rare events
Circuit breakers are everywhere—but things still fail
Async systems tolerate slowness. Sync systems amplify it.
Over-Centralized Logic: The Birth of the “God Service”
A God service isn’t defined by size. It’s defined by importance.
A service becomes a God service when:
Many workflows depend on it
It knows too much about other domains
Changes to it require cross-team coordination
Downtime affects unrelated features
Ironically, God services often emerge from good intentions:
“We need a single place for this logic.”
“Let’s centralize validation.”
“It’s easier if one service decides.”
Centralization feels clean—until it scales.

Why God Services Are Hard to Kill
God services resist refactoring because:
They are deeply embedded
They feel “too critical to change”
Teams build around them instead of through them
The longer they live, the more gravity they accumulate.
Horizontal Scaling Realities: Scale the Right Axis
Horizontal scaling is not magic replication.
It works when:
Work can be split independently
State is externalized or partitioned
Ordering constraints are minimal
It fails when:
A single decision point serializes work
State is shared implicitly
Components depend on global knowledge

Scaling isn’t about more instances. It’s about less coordination per instance.
Knowing When to Split Components
Splitting too early creates overhead. Splitting too late creates paralysis.
Good reasons to split:
Independent scaling needs
Distinct failure modes
Clear ownership boundaries
Diverging change rates
Bad reasons to split:
“Microservices are cool”
Code size discomfort
Organizational politics

A useful heuristic:
If two responsibilities fail differently, they should not live together.
Recognizing Architectural Smells Early
Most scaling failures are preceded by signals:
Queue lag creeping upward
Retry rates increasing slowly
One service appearing in every incident
Engineers afraid to touch certain components

These are not operational issues. They are architectural feedback.
Ignoring them doesn’t make them go away. It just lets them mature into outages.
Scaling Is an Ongoing Conversation
The most dangerous belief in system design is:
“We solved scaling.”
Scaling is not a milestone. It’s a dialogue between load, structure, and intent.

Healthy teams:
Regularly revisit boundaries
Refactor before emergencies
Treat bottlenecks as information
Value simplicity over cleverness
Where We Go Next
Up to this point, we’ve explored patterns, principles, and failure modes in the abstract—what scales, what breaks, and why. Now it’s time to ground those ideas in reality. In the next article, we begin Part 3: Case Study — My CSL Datahub Implementation, starting with Introducing the CSL Datahub: Context and Constraints, where we’ll look at the real-world requirements, trade-offs, and limitations that shaped an actual production system.




