

BFF vs API Gateway vs GraphQL: Picking the Right Abstraction
Comparative analysis with real trade-offs. Where each pattern wins, where it falls over, and how they can coexist.
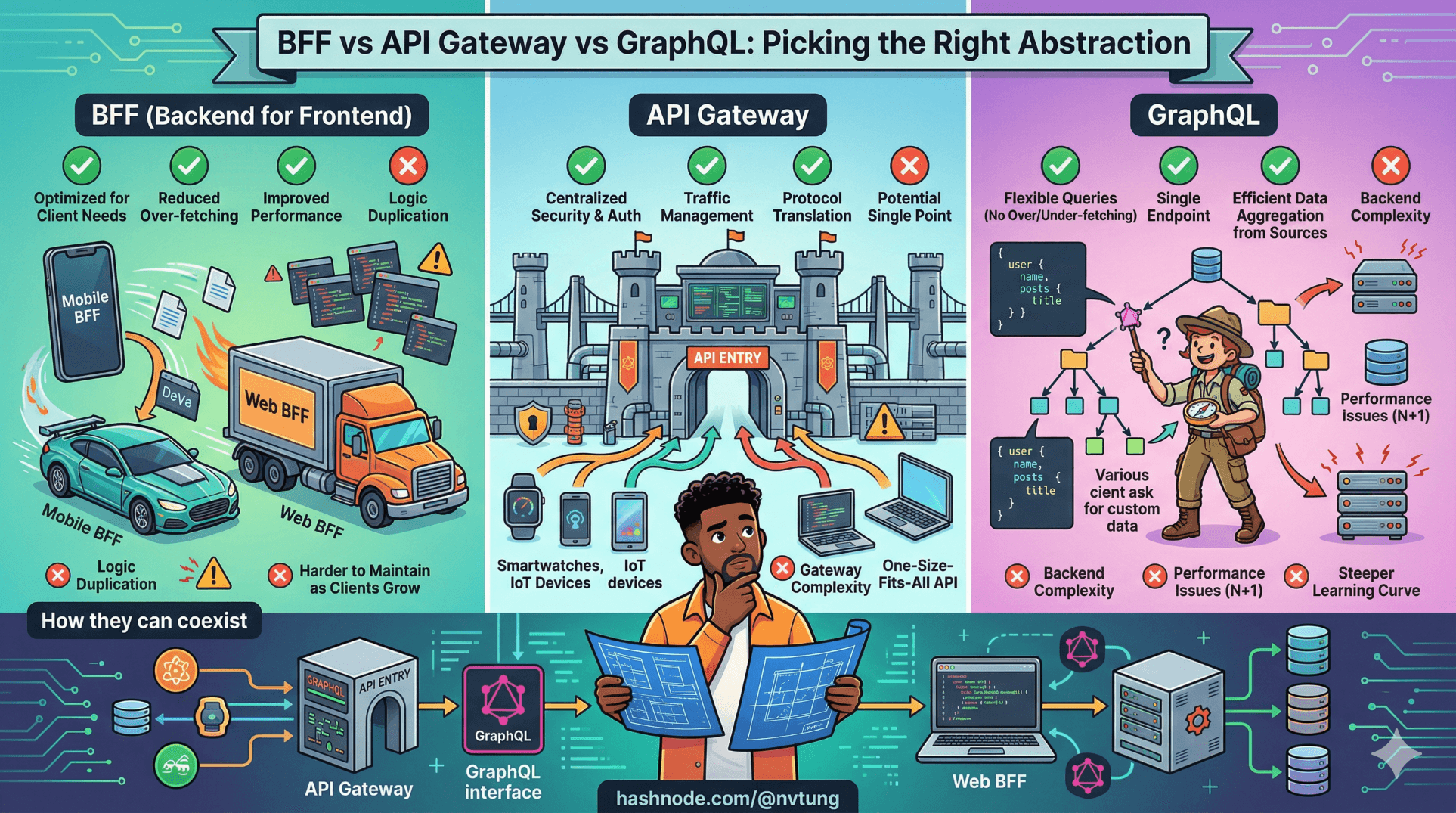
Before writing a single line of BFF code, one question deserves a direct answer: is BFF actually the right abstraction for your situation, or would an API Gateway or GraphQL solve the same problems with less overhead?
This is not a rhetorical question. All three patterns address the same underlying tension — the mismatch between what backend services expose and what frontend clients need — but they address it differently, at different layers, with different cost profiles and different failure modes. Choosing the wrong abstraction early is expensive to undo. Choosing the right one requires understanding not just what each pattern does, but what each pattern is designed to resist.
This article gives each pattern a fair hearing, identifies where each genuinely wins, and then addresses the question every architect eventually faces: can they coexist, and if so, how?
The common problem, three different answers
All three abstractions exist because of the same structural tension: backend services are organised around domain entities and service boundaries; frontend clients are organised around screens, interactions, and user tasks. These two organisational principles produce different, often incompatible data shapes.
The three patterns answer this tension differently:
API Gateway says: standardise the entry point, enforce cross-cutting concerns, and route requests to the right service — but leave shape and aggregation to the client or the services themselves.
GraphQL says: let the client declare exactly what data it needs in a single query, and build a schema that spans service boundaries so the server can resolve it.
BFF says: create a dedicated server-side layer, owned by the frontend team, that aggregates and shapes data specifically for one client surface.

Each answer implies a different locus of complexity. API Gateway concentrates complexity in infrastructure. GraphQL concentrates it in the schema and resolver layer. BFF concentrates it in the service itself. Where you want that complexity to live — and who you want to own it — is a significant part of the decision.
API Gateway
What it is designed to do
An API Gateway sits at the network perimeter and handles concerns that apply uniformly across all traffic entering the system: authentication and authorisation enforcement, rate limiting, TLS termination, request routing, logging, and protocol translation. In Azure, this is Azure API Management. In AWS, it is Amazon API Gateway. In a self-managed cluster, it might be Kong or Nginx.
The Gateway's job is to be a consistent, reliable entry point — not to understand what any individual client needs from any particular service. It routes a request to the right upstream service and returns what that service returns, perhaps with light transformation, caching, or throttling applied.
Where it wins
Cross-cutting concerns at scale. Rate limiting, IP allowlisting, API key management, OAuth 2.0 token validation, and request logging are applied once, at the Gateway, and are invisible to every upstream service. Without a Gateway, each service implements these independently, inconsistently, and at higher total cost. This is the Gateway's clearest and most defensible value.
Protocol and version mediation. A Gateway can expose a REST interface in front of gRPC services, or route v1 requests to legacy services while v2 requests go to new implementations — without the client needing to know the upstream topology changed. This is particularly valuable during service migrations.
Traffic management. Circuit breaking, retry policies, canary routing, and A/B traffic splitting are Gateway-layer concerns that do not belong in application code. A well-configured Gateway protects upstream services from traffic spikes and provides the operational levers to manage deployments safely.
Where it falls over
It does not solve the aggregation problem. A Gateway routes requests; it does not compose them. A screen that requires data from four services still requires four round trips from the client, or a Gateway orchestration configuration so complex it is effectively a new service in disguise. Some Gateways support request aggregation through scripting (Kong's Lua plugins, APIM's policies), but this is instrumenting infrastructure to do application logic — a direction that leads to unmaintainable policy files.
It cannot be client-specific. A Gateway enforces the same behaviour for all clients. A web application, a mobile app, and a third-party integration all receive the same treatment. Response shapes cannot differ per client without replicating route configurations and transformation rules, which does not scale.
Frontend teams do not own it. The Gateway is typically owned by a platform or infrastructure team. A frontend team that needs a new field in a response shape, or a different error format, or a caching policy for a specific endpoint, must file a request and wait. This is not a process failure — it is the correct operational model for shared infrastructure. But it means the Gateway cannot provide the autonomy that makes BFF valuable.
The right use of API Gateway in a BFF architecture
API Gateway and BFF are not alternatives — they are layers. The Gateway handles what the Gateway is designed to handle: network-level concerns, security perimeter enforcement, traffic management. The BFF sits behind it and handles what the BFF is designed to handle: aggregation, shaping, and client-specific logic.
In the production system this series is based on, Azure API Management sits in front of the BFF service. APIM handles TLS termination, JWT validation at the network boundary, rate limiting, and request logging. The BFF handles everything downstream of that: Feide session management, upstream service aggregation, and Vue-specific response shaping. Neither layer does the other's job.

GraphQL
What it is designed to do
GraphQL is a query language and runtime that lets clients declare exactly what data they need in a single request. Rather than multiple endpoints returning fixed shapes, GraphQL exposes a single endpoint backed by a typed schema. The client sends a query document specifying which fields it needs; the server resolves the query by calling whatever data sources are necessary and returns exactly the requested fields.
In a microservices context, this typically means a GraphQL server (or federation layer) that stitches together schemas from multiple services and resolves queries by delegating to the appropriate service.
Where it wins
Client-driven data fetching. The defining advantage: the client gets exactly what it asks for, nothing more and nothing less. Overfetching and underfetching are structurally eliminated — or at least structurally addressable. A product team that iterates quickly on screens, changing which fields a component needs from sprint to sprint, does not need to modify a backend service or a BFF to change its data requirements. It changes the query.
Unified schema across services. A GraphQL federation layer provides a single, coherent graph that spans multiple backend services. From the client's perspective, there is one API. The fact that User comes from the identity service, Course comes from the course service, and Session comes from the scheduling service is invisible. This is genuinely powerful in systems with many services and complex cross-entity queries.
Introspection and tooling. GraphQL's introspection system means the schema is self-documenting and tooling (GraphiQL, Rover, generated TypeScript types via graphql-codegen) works out of the box. The development experience for querying data is hard to match.
Incremental adoption. A GraphQL schema can be introduced in front of existing REST services without replacing them. The GraphQL resolvers call the REST endpoints. This makes adoption less disruptive than a full architectural change.
Where it falls over
It does not eliminate the aggregation problem — it moves it. A GraphQL server still has to call multiple upstream services to resolve a query. The N+1 problem — where resolving a list of N items triggers N additional queries — is one of the most common production performance issues in GraphQL systems, and solving it requires the DataLoader pattern, batching strategies, and careful resolver design. This complexity is real and non-trivial.
Caching becomes harder. REST's GET semantics map naturally to HTTP caching. GraphQL queries are typically POST requests with variable query documents, which HTTP caches cannot cache at the network layer. Caching in GraphQL requires application-level cache implementations (persisted queries, response caching with cache hints, Apollo Cache), all of which add complexity. For systems where caching is a primary performance lever, this is a significant cost.
Security surface is wider and less obvious. A single endpoint that accepts arbitrary query documents is a different security model from discrete REST endpoints with defined inputs. Query depth limiting, query complexity analysis, and field-level authorisation all require explicit implementation. A naive GraphQL deployment is vulnerable to expensive query attacks that a REST API with fixed response shapes is not.
It is best owned by a team that knows it well. GraphQL federation, resolver design, DataLoader implementation, and schema governance are non-trivial specialisms. Teams adopting GraphQL without prior experience tend to underestimate the ongoing maintenance cost of schema evolution, breaking change management, and performance debugging. The tooling is excellent, but the learning curve is real.
Client-specified queries are a double-edged sword. The ability for clients to request arbitrary field combinations means the server cannot pre-optimise data fetching for known query patterns. A BFF, by contrast, knows exactly what every screen needs and can fetch exactly that — predictably, efficiently, with a query plan that never changes.
When GraphQL is the right choice over BFF
GraphQL genuinely outperforms BFF in two scenarios.
First, when the number of screens is large and they share overlapping data needs in complex, variable combinations. A content platform with hundreds of screen types, or a developer-facing API with many unknown consumers, benefits from GraphQL's flexibility in ways a BFF — designed for a finite set of known screens — does not.
Second, when product iteration velocity is high enough that the cost of updating a BFF endpoint for every UI change becomes a bottleneck. If engineers are changing which fields a component displays every sprint, and a BFF change is required for each change, the BFF is adding friction without adding enough stability to justify it. GraphQL's client-driven model removes that friction.
For the production education platform this series describes — a finite set of known screens, authenticated users with role-based data access, and specific caching requirements for institutional data — BFF was the right call. The screens were well-defined, the data relationships were consistent, and the security model (Feide token exchange, server-side sessions) required server-side ownership of the authentication boundary. GraphQL would have added schema complexity without providing flexibility the product needed.

Comparison at a glance
| Concern | API Gateway | GraphQL | BFF |
|---|---|---|---|
| Owns aggregation | No | Yes (resolver layer) | Yes |
| Client-specific shaping | No | Partial (field selection) | Yes (by design) |
| Caching (HTTP-level) | Yes | Difficult | Yes |
| Security boundary | Perimeter only | Application-level | Full (session + token) |
| Frontend team ownership | No | Shared | Yes |
| Schema/type safety | Via spec only | Native | Via OpenAPI |
| N+1 risk | N/A | High without DataLoader | Low (controlled fetching) |
| Learning curve | Low–Medium | High | Medium |
| Breaking change risk | Low | Medium (schema evolution) | Medium (contract versioning) |
| Best at | Cross-cutting concerns | Flexible client queries | Known client, stable screens |
Coexistence: the architecture that actually works in production
The question "BFF vs API Gateway vs GraphQL" is framed as a choice. In practice, production systems at meaningful scale use more than one of these, because they solve different problems.
The most common and defensible combination is:
Client
│
▼
API Gateway ←── TLS, auth enforcement, rate limiting, logging
│
▼
BFF Service ←── Aggregation, shaping, session management
│ │ │
▼ ▼ ▼
Upstream services
The Gateway provides network-level security and traffic management. The BFF provides client-specific API logic. Each layer does exactly one thing and does not bleed into the other's responsibilities.
Adding GraphQL into this picture is less common but not unusual, typically in one of two configurations:
GraphQL as the BFF's internal query mechanism. Rather than the BFF making REST calls to upstream services, it queries a GraphQL federation layer internally. The Vue application still talks REST to the BFF — it is shielded from GraphQL entirely. This gives the BFF the flexibility of GraphQL's data graph internally while maintaining a stable, cacheable REST contract externally. This configuration makes sense when upstream services are already federated under GraphQL and the BFF is being added in front of an existing system.
GraphQL exposed alongside the BFF for different consumers. The BFF serves the primary Vue web application. A separate GraphQL endpoint serves mobile applications or third-party developers who benefit from flexible querying. Both sit behind the same Gateway. This is the "one BFF per client surface" model applied to heterogeneous client types — web gets a BFF optimised for its screens, mobile and external consumers get GraphQL's flexibility.
What does not work is all three patterns collapsing into a single layer with no clear ownership boundaries. A GraphQL server that also enforces rate limits that also does session management is a system where no one understands why anything is configured the way it is, and where changes in one concern break another.

Making the call
The choice comes down to three questions, asked honestly:
Who owns the API layer? If the answer is "a platform team," Gateway-first is the natural model. If the answer is "the frontend team," BFF gives that team the autonomy its ownership implies. If the answer is "unclear," that ambiguity should be resolved before the architecture decision.
How well-defined are the client's data needs? Known screens with stable data requirements favour BFF — the predictability is a feature, not a limitation. Variable, exploratory, or numerous distinct query patterns favour GraphQL. Infrastructure-layer concerns with no client-specific logic favour Gateway only.
What is the team's operational capacity? GraphQL federation is not simple to operate. BFF adds a service to maintain. Gateway-only is the lowest operational floor. Be honest about what your team can sustain, and choose an architecture whose operational cost falls within that ceiling.
For the real production web app used as the model this series — a single Vue web application, authenticated via Feide, deployed to Azure, serving a defined set of screens for a specific user population — BFF behind an Azure API Management Gateway is the right architecture. The remaining articles build it out in full.




